 客户服务热线
客户服务热线客服邮箱:service@midu.com
总部地址:上海市浦东新区张衡路198弄10号楼3层

在线
咨询
官方
客服
电话
咨询
关注
公众号
问题
反馈
返回
顶部
在线
咨询
问题
反馈
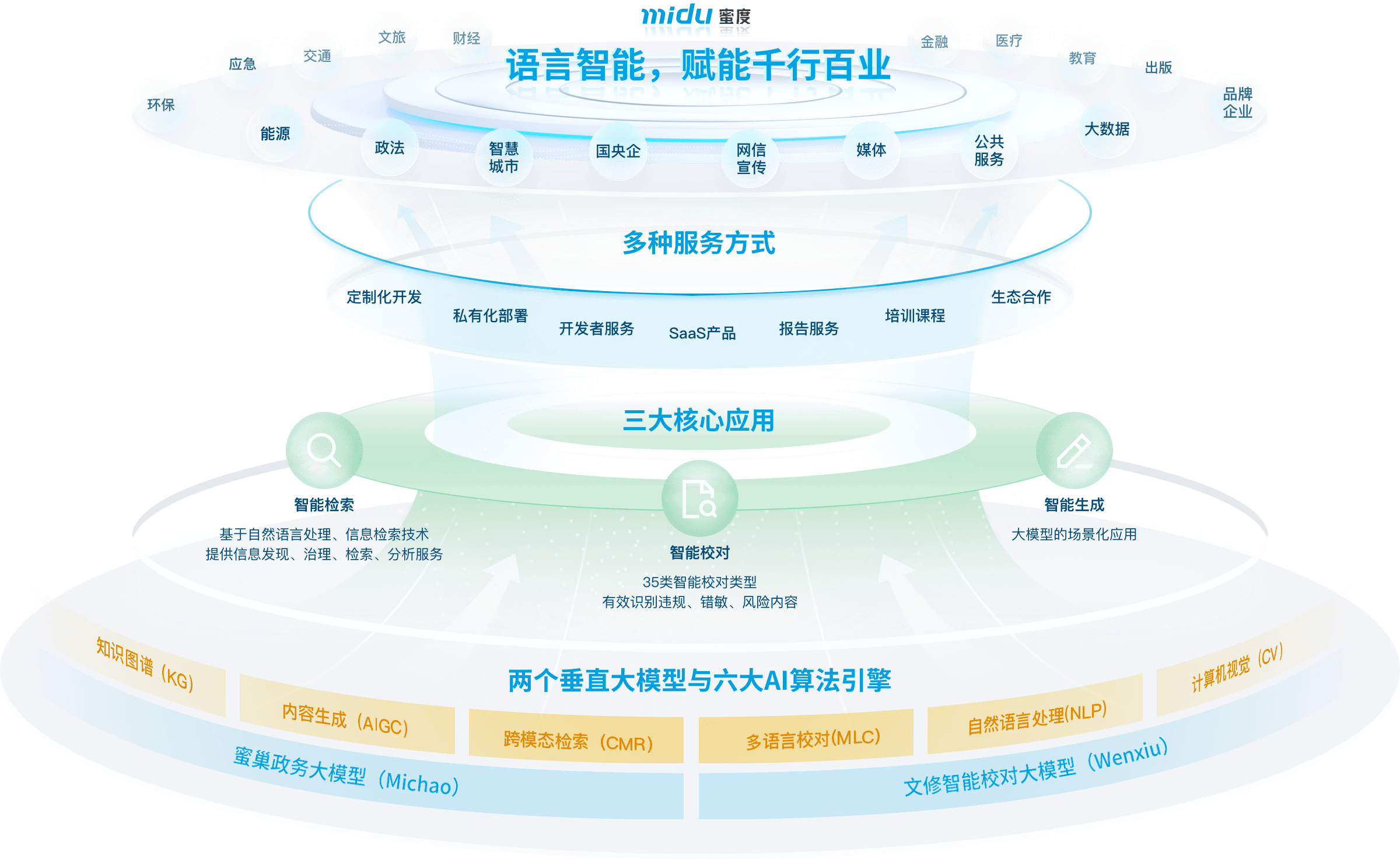


大模型
智能校对大模型
自主:蜜巢为蜜度自主研发的大模型,在研发工作中,构建了Token数超1万亿、中文内容占比超75%的高质量语料数据集用于预训练工作。
安全:蜜巢从优质预训练语料入手,从零开始逐阶段完成训练,同时从源头强化价值观对齐能力与中文理解能力,模型安全可信、自主可控。
双引擎:基于自主研发的蜜巢大模型,并融合书生·浦语大模型,通过构建“双引擎”协同机制,推动各类应用场景的深度开发与高效落地实施。
应用丰富:模型聚焦知识问答、公文写作、材料分析三大垂直应用方向,以蜜巢能力为核心,不断拓展大模型的应用场景,为各垂直办公领域赋能。
落地强:蜜巢大模型已完成备案,并落地蜜度文稿通、知知通、新浪舆情通三款智能应用产品,为1万+客户提供SaaS服务。同时,也为客户提供个性化大模型解决方案,并已在包括政务服务热线、大型企业内部知识管理与问答、社交媒体智能舆情分析等多个场景实现商业化落地。
安全可控:以大模型 (LLM )为技术底座,从零训练,确保技术自主;具备大规模高质量数据构造能力,数据可控;支持在消费级显卡上以容器化方式实现快速部署,单节点处理千字文本仅需0.5秒,成本可控;
技术优越:引入样例增强和解码增强技术提高校对效果;
高质量数据:基础预训练模型的数据超10000亿词符,校对任务的训练数据超5000亿词符,校对训练数据规模达8000亿Token;
效果优秀:面向母语和非母语的公开测试数据集,截至目前,在所有公开结果中文修表现效果最佳。面向专业领域公开数据集,文修能够识别并准确纠正的差错案例占比超70%;










MiduMLC多语言校对引擎基于去噪自编码与自回归技术,将大规模语料库中蕴含的语言规律内嵌到深度网络模型之中,并通过音形义多模态融合和文本约束生成,实现对多种语言文字内容的智能校对与改写,校对能力处于业界前沿地位。
MiduMLC支持文本、图片、视频等多模态数据与网页、版式、流式等多文档格式的智能解析与校对,并拥有动态更新的知识图谱和常识知识库,具有精准的多要素实体关系联合抽取模型和事实一致性检测能力。MiduMLC具备主动学习能力,能够在无人工干预下持续提升校对效果。

MiduNLP是面向工业场景的智能引擎,具备敏捷开发、自定义等优点。借助大规模的语料库,训练了丰富的语言模型。引擎能力涵盖分词、命名实体识别、关键词提取、新词发现、关系抽取、情感分析等自然语言处理任务,可满足工业场景中对文本处理的各类技术需求。引擎持续跟踪业界前沿算法模型,助力模型的便捷实现、高效训练和快速落地。

MiduCV作为面向图片、语音、视频等模态内容的智能理解引擎,涵盖了CV及ASR等技术方向。引擎模型包括目标检测、语义分割和卷积循环神经网络等,实现光学字符识别、人脸识别、以图搜图、特定目标检测、视频理解等任务。依托上述技术并结合工业场景进行针对性优化与融合,实现图片、视频两种模态内容中图片文字、视频字幕、人物、场景及品牌Logo的提取与识别。
针对智能语音识别,引擎则通过搭建的语音活动检测模型和自动语音识别模型,结合实际工业场景的精标数据集进行模型的自主训练及性能优化,解决了对语音片段的自动降噪、精准提取与准确识别等问题,实现对音频内容的智能识别与理解。

MiduCMR涵盖了NLP、CV单一模态以及多模态之间进行交互、融合的技术。相较于单一模态的模型,跨模态可以真正实现“以语言指导图像,以图像指导语言”的训练,充分利用不同模态之间的互信息来提升模型对各种模态的理解能力。
引擎采用泛化性及效果突出的Transformer架构模型,不仅在单模态认知中能够通过自注意力机制充分学习特征,也能在多模态认知过程里充分融合不同模态的特征,从而达到多模态信息表示的统一。引擎通过基于动量对比学习、跨模态融合注意力、以及跨模态特征指导等工作,在大量无监督数据上进行预训练,并针对不同工业场景进行特化训练。
引擎能力覆盖各种跨模态检索任务(文搜图、图搜文、文搜视频等)、单模态检索任务(相似图片检索)、图片描述生成任务、图文匹配判断任务等。

MiduAIGC内容生成引擎,支持在不同的模态及任务场景上进行辅助内容生成。MiduAIGC引擎在学界业界最新模型基础上进行模型设计,认知并融合中文语言环境下多模态内容的特性开展语言模型训练,支持根据用户要求辅助生成相应内容。目前MiduAIGC引擎专注于图生图,图生文,文生图,文生文能力的建设。
文生文:拥有续写,文稿撰写能力,可以辅助用户进行文字创作,提供创作灵感,大大提升用户的创作效率。
文生图:可根据用户输入的文字进行艺术创作、图像编辑,可根据简笔画草图与文字要求可控地生成图像。可以在设计、配图等多个场景辅助用户进行创作。
图生图:由图像风格迁移,超分辨率,图像修复等多个能力构成,共同帮助用户对图像进行智能美化与修改。
图生文:可以根据图片内容进行文字创作,可用于图片描述生成,图片相关的广告文字生成,以及基于图像内容的问答等。

MiduKG知识图谱引擎通过知识建模、知识抽取、知识融合、知识存储、知识计算等技术从海量文本、图像、音视频等多模态信息中提取有价值的知识,同时采用深度学习技术来推断复杂知识的关联关系,从而形成对知识的认知,并自动构建知识图谱。并用于解决语义搜索、智能推荐、知识问答和知识可视化等多种复杂场景的问题。
语义搜索:利用知识图谱中的知识模型,实现用户输入的自然语言查询逻辑的解析。
智能推荐:从海量的信息中为用户寻找其感兴趣的信息,通过算法推荐达到节省用户时间、提升用户满意度。
知识问答:利用了知识图谱中知识模型以及推理能力,以多轮交互的方式实现用户问题的回答。
知识可视化:利用了知识图谱中的已有知识,可以将知识结构可视化展现出来,从而更好的展示出知识之间的联系。

个性化解决方案满足用户特定需求

按需求进行本地化部署

提供标准化产品服务

提供基于产品功能的一系列开发者服务

系统+人工实时推送,支持定制化分析报告

共建创新实验室、联合会销活动、产品展示等,推动行业发展



了解详情


了解详情


了解详情


 沪公网安备 31011502018407号
沪公网安备 31011502018407号 电子营业执照
电子营业执照